在互联网时代,每时每刻都有大量的内容被生产出来,不论是短视频还是传统影视作品,都是人穷尽一生也无法看完的。将内容与其目标受众连接起来,是影视平台的主要任务。除了用户主动的检索行为之外,通过推荐算法所得出的主页展示是另外一条途径。

在众多影视平台之中,Netflix算是影像内容个性化推荐的先行者。它从2006年悬赏百万美元进行推荐算法大赛开始,就一直致力于不断优化面向用户消费需求的影像内容推荐系统。如今,Netflix用户平均每3个小时的视频播放时长中就有2个小时是来自于首页的推荐内容。
Netflix的现行的推荐算法综合考虑到短期热点,用户的兴趣点以及用户的观看场景。除了用于推荐内容本身之外,推荐算法还用于平台选择推荐方式。Netflix针对每一部电影都制作了30-40份海报,每份海报的侧重点不同。由于每一部电影对于不同人的吸引点也各不相同,有的因为类型对胃口,有的因为某位明星加盟,所以Netflix通过将侧重点各异的海报分发到不同的受众群体,以提升播放的转化率。
相较而言,国内的视频平台的推荐算法起步较晚,但是发展迅猛。爱奇艺于2013年推出了业界第一个智能推荐的客户端,仅两年之后,用户浏览的推荐内容就占到了总流量的30%。
优酷的个性化推荐则从2017年下半年开始部分推行,2018年才全面推广。不过凭借阿里的庞大用户数据,优酷在用户肖像上有着天然的优势。2018年优酷认知实验室成立,在视频结构分析和内容智能生成上进行了提升改进。视频的结构分析也就是直接从声画中提取信息,进一步精细化视频元素;而内容智能生成主要应用于海报,以达到前述Netflix推荐方式个性化的效果。
可以说,推荐算法是各大影视平台博弈中的重要战场。

人工智能还是人工智障
说起来,推荐算法自诞生伊始就跟影视有着深厚的渊源。
推荐算法的研究起源于20世纪90年代,由美国明尼苏达大学 GroupLens研究小组最先开始研究,他们想要制作一个名为 Movielens的电影推荐系统,从而实现对用户进行电影的个性化推荐。首先研究小组让用户对自己看过的电影进行评分,然后小组对用户评价的结果进行分析,并预测出用户对并未看过的电影的兴趣度,从而向他们推荐从未看过并可能感兴趣的电影。
也就是说,早在彼时算法的逻辑就已经初具雏形了,互联网时代的到来为算法提供了大量的可供处理的信息,此后,推荐算法才成为视频平台的制胜法宝。
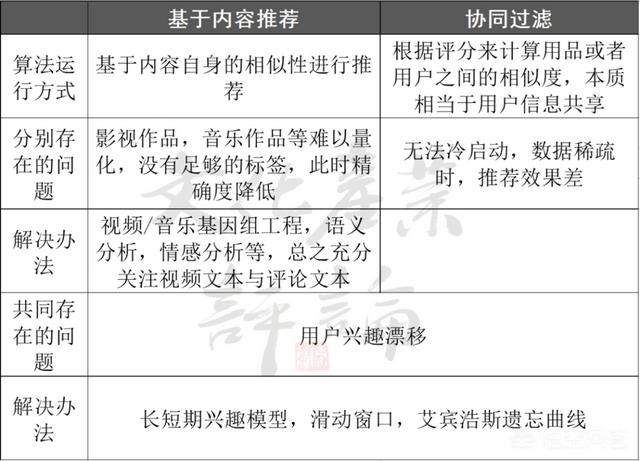
总结起来,现在各影视平台所用的纷繁复杂的推荐算法不外乎两条根本逻辑:一个是协同过滤算法,一个是基于内容的推荐算法。
协同过滤算法(Collaborative Filtering,简称CF),也就是根据所有用户的历史数据,来推测每个用户当下所可能感兴趣的内容。这种方法将用户-内容的评级矩阵作为输入数据,输出的则是用户对每一个尚未接触过的内容的预估兴趣值,并依次将内容排序推荐给用户。
协同过滤算法的优势是不需要关于内容本身的任何参数,也就是说,内容是什么不重要,谁喜欢它才重要。因此,许多平台的相似推荐会采用“喜欢这部电影的人也喜欢”这种表述。同样,当韩国导演洪尚秀的电影《引见》的相似推荐中,同时出现蔡明亮、滨口龙介和赫尔佐格的作品时,我们也就不必惊讶,因为在协同过滤的逻辑下,正是影迷的选择造就了不同时期、不同国别、不同风格的导演之间强有力的连结。
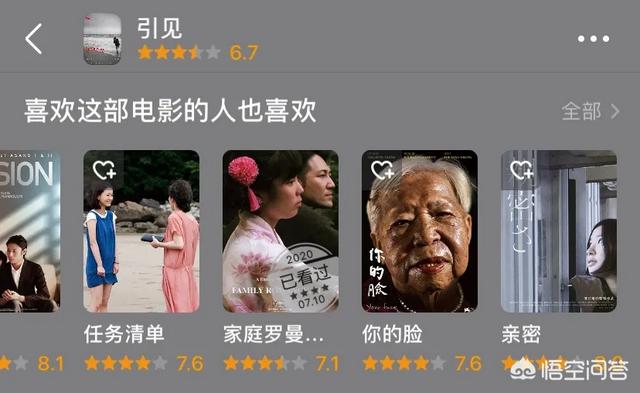
由于不需要关于内容的任何信息,协同过滤算法被广泛应用于电影和音乐这种难以量化的内容的推荐上。它最大的问题就是需要丰富的历史数据和庞大的用户群体,因此难以应用于平台诞生之初。
第二种是基于内容的推荐算法(Content-Based Filtering简称CBF),也就是根据内容的分类信息为用户推荐相似的内容。此时的输入数据是用户的偏好,以及内容的属性,输出的是最符合用户偏好的内容。
不难想象,对于影视而言,基于内容的推荐算法最大的挑战来源于影视内容的难以量化,往往要使用高昂的人工成本。在这方法做到极致的仍是Netflix。
早在2006年,Netflix产品副总裁托德·耶林便带领团队为影视内容贴上“微标签”。这一方法也被其设计者赋予一个极具数理色彩的名称——“Netflix量子理论”。在具体操作中,Netflix雇佣独立评论者来看片,并从1000多个标签中进行选择以描述他们所看到的内容,如血腥程度,浪漫程度,情节结论性等,由此生成了丰富的“微类型”。微类型的总量竟达76897种之多,比如“情感充沛的反体制纪录片”“基于真实生活的皇室掠影”,都是所谓的“微类型” ,其描述方式几乎要突破语言的极限。
基于内容的推荐算法需要耗费大量人力,协同过滤算法则难以应对缺乏数据的“冷启动”过程。此外,两种算法所共同面临的另一个难题是用户兴趣漂移,即用户的兴趣点随着时间变化,长期推送相似的内容会让用户感到乏味。为此,许多模型通过加入艾宾浩斯遗忘曲线,滑动窗口,长短期兴趣模型等方法进行改进。
不过,有时算法所设定的过快的更换速度也容易让用户措手不及。假如用户本着好奇心进入了自己本不熟悉的内容,又一不小心看完了,结果第二天首页可能被相似内容全部占领。说到底每个人的遗忘速度也是不一样的。人心难测,和所有现在的弱人工智能一样,推荐算法距离测量人心还有相当的距离。
标签: #算法